01 임베딩과 벡터에 대한 이해
1. 임베딩(Embedding)과 벡터(Vector)란 무엇일까요?
Section titled “1. 임베딩(Embedding)과 벡터(Vector)란 무엇일까요?”최근 챗GPT와 같은 대형 언어 모델(LLM)이 우리 일상에 깊게 자리 잡으면서, ‘임베딩’이나 ‘벡터’라는 기술 용어를 자주 접하게 됩니다. 이 두 가지는 인공지능이 인간의 언어를 이해하는 데 있어 가장 기초적이고 중요한 뼈대 역할을 합니다.
자연어 처리(NLP) 분야에서는 우리가 사용하는 단어나 형태소 같은 언어의 조각들을 **‘토큰(Token)‘**이라고 부릅니다. 그런데 컴퓨터는 ‘사과’, ‘사랑’ 같은 인간의 문자를 그대로 이해하지 못합니다. 컴퓨터는 오직 ‘숫자(0과 1)‘만 연산할 수 있기 때문입니다.
따라서 기계가 인간의 언어를 이해하게 만들려면, 자연어를 기계가 읽을 수 있는 숫자들의 나열로 번역해 주는 과정이 필요합니다. 이 번역 과정을 **‘임베딩(Embedding)‘**이라고 부르며, 그 결과물로 나온 숫자들의 묶음을 **‘벡터(Vector)‘**라고 부릅니다. 쉽게 말해 언어를 숫자로 암호화하는 작업이라고 생각하시면 됩니다.
텍스트를 컴퓨터가 이해하고, 효율적으로 처리하게 하기 위해서는 컴퓨터가 이해할 수 있도록 텍스트를 적절히 숫자로 변환해야 합니다. 단어를 표현하는 방법에 따라서 자연어 처리의 성능이 크게 달라지기 때문에 단어를 수치화 하기 위한 많은 연구가 있었고, 현재에 이르러서는 각 단어를 인공 신경망 학습을 통해 벡터화하는 워드 임베딩이라는 방법이 가장 많이 사용되고 있습니다.
성능이 좋은 AI 모델을 만들기 위해서는 이 ‘숫자 번역(임베딩)‘이 얼마나 정교하게 잘 되어 있는지가 매우 중요합니다. 단어의 숨은 뜻이나 뉘앙스까지 숫자로 잘 담아내야 인공지능이 똑똑하게 대답할 수 있기 때문입니다.
2. 가장 단순한 방식: 원-핫 벡터 (One-hot Vector)
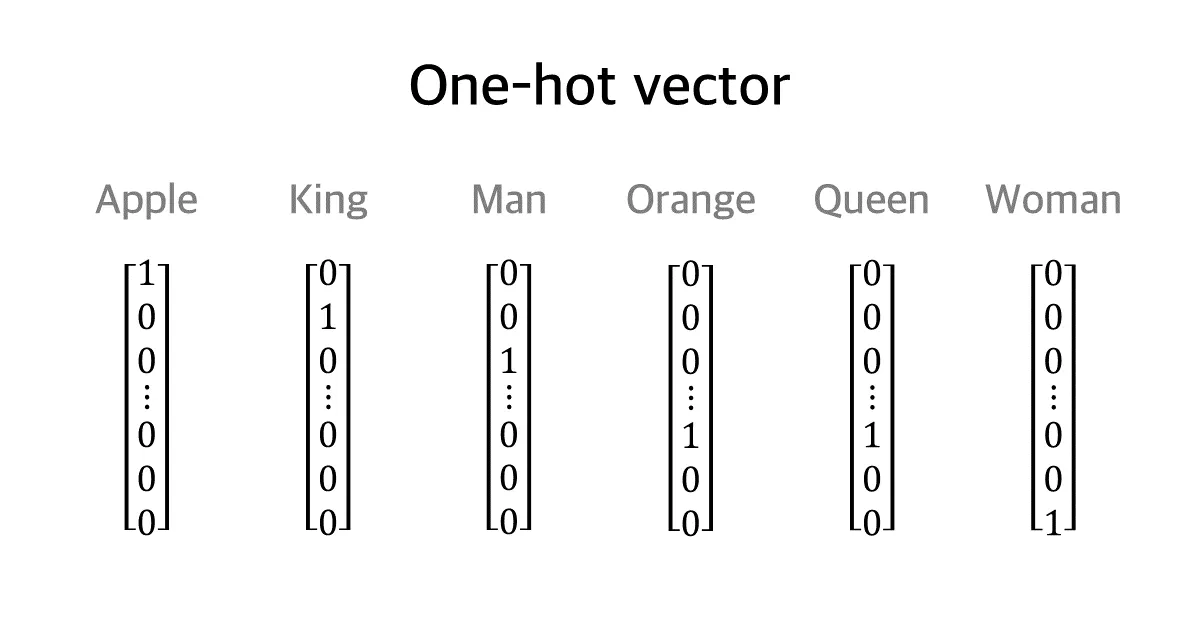
Section titled “2. 가장 단순한 방식: 원-핫 벡터 (One-hot Vector)”단어를 숫자로 바꾸는 가장 쉽고 단순한 방법은 **원-핫 벡터(One-hot Vector)**입니다. 이름 그대로 ‘단 하나의 위치에만 불(1)을 켜고, 나머지는 모두 끄는(0)’ 방식입니다.
-
동작 원리: 만약 우리가 가진 전체 단어 사전이 10,000개의 단어로 이루어져 있다고 가정해 보겠습니다. 그렇다면 10,000칸짜리 빈칸(리스트)을 만듭니다. 그리고 해당 단어가 있는 고유한 순서(인덱스)에만 1을 적고, 나머지 9,999개의 칸에는 모두 0을 적습니다.
-
예시:
-
Apple = [1, 0, 0, 0, …, 0] (첫 번째 단어)
-
Banana = [0, 1, 0, 0, …, 0] (두 번째 단어)
-
Woman = [0, 0, 0, 0, …, 1] (마지막 단어)
-
희소 표현(Sparse Representation)
Section titled “희소 표현(Sparse Representation)”앞서 원-핫 인코딩을 통해서 나온 원-핫 벡터들은 표현하고자 하는 단어의 인덱스의 값만 1이고, 나머지 인덱스에는 전부 0으로 표현되는 벡터 표현 방법이었습니다. 이렇게 벡터 또는 행렬(matrix)의 값이 대부분이 0으로 표현되는 방법을 희소 표현(sparse representation)이라고 합니다. 원-핫 벡터는 희소 벡터(sparse vector)입니다.
이러한 희소 벡터의 문제점은 단어의 개수가 늘어나면 벡터의 차원이 한없이 커진다는 점입니다. 원-핫 벡터로 표현할 때는 갖고 있는 코퍼스에 단어가 10,000개였다면 벡터의 차원은 10,000이어야만 했습니다. 심지어 그 중에서 단어의 인덱스에 해당되는 부분만 1이고 나머지는 0의 값을 가져야만 했습니다. 단어 집합이 클수록 고차원의 벡터가 됩니다. 예를 들어 단어가 10,000개 있고 인덱스가 0부터 시작하면서 강아지란 단어의 인덱스는 4였다면 원 핫 벡터는 이렇게 표현되어야 했습니다.
Ex) 강아지 = [ 0 0 0 0 1 0 0 0 0 0 0 0 … 중략 … 0] # 이때 1 뒤의 0의 수는 9995개.
이 방법은 마치 단어마다 바코드를 부여하는 것과 같아서, 컴퓨터가 “이 단어와 저 단어는 서로 다른 단어구나”라고 구별할 수는 있습니다. 하지만 치명적인 단점이 있습니다. 단어들 사이의 관계나 의미를 전혀 알 수 없다는 점입니다. 예를 들어 인간은 ‘Apple’과 ‘Banana’가 모두 과일이라는 것을 알지만, 원-핫 벡터 방식에서는 두 단어가 그저 1의 위치가 다른 남남일 뿐입니다. 언어에서 가장 중요한 ‘의미’를 담아내지 못하는 것입니다.
3. 단어의 진짜 의미를 담는 그릇: 분산 표현 (Distributed Representation)
Section titled “3. 단어의 진짜 의미를 담는 그릇: 분산 표현 (Distributed Representation)”모든 것은 ‘분포 가설’에서 시작됩니다
Section titled “모든 것은 ‘분포 가설’에서 시작됩니다”분산 표현이라는 기술은 언어학의 아주 중요한 철학 하나를 밑바탕에 깔고 있습니다. 바로 **‘분포 가설(Distributional Hypothesis)‘**입니다.
말이 조금 어렵지만, 뜻은 아주 단순합니다.
“비슷한 문맥(주변)에서 등장하는 단어들은 서로 비슷한 의미를 가진다.”
예를 들어 **‘강아지’**라는 단어를 생각해 보겠습니다. 우리가 평소에 글을 쓰거나 말을 할 때, ‘강아지’ 주변에는 주로 ‘귀엽다’, ‘예쁘다’, ‘애교’, ‘간식’ 같은 단어들이 짝꿍처럼 자주 등장합니다. 분포 가설은 이 점에 착안하여, *“이렇게 주변에 비슷한 단어들을 데리고 다니는 녀석들은 그 의미(벡터 값)도 비슷하게 만들어주자!”*라고 접근하는 방식입니다.
의미를 여러 칸에 ‘분산’ 시켜서 저장하기
Section titled “의미를 여러 칸에 ‘분산’ 시켜서 저장하기”그렇다면 어떻게 컴퓨터의 숫자(벡터)로 이 의미를 표현할까요? 원-핫 벡터처럼 단어마다 자신만의 지정석(1개의 칸)을 주고 나머지는 다 0으로 비워두는 방식이 아닙니다.
대신, 단어가 가진 복합적인 의미와 특성들을 여러 개의 칸(차원)에 골고루 ‘분산’시켜서 실수(소수점이 있는 숫자)로 꽉꽉 채워 넣습니다. 그래서 이름이 ‘분산 표현’인 것입니다. 앞서 3번 항목에서 잠시 설명해 드렸던 ‘임베딩 벡터’가 바로 이 분산 표현을 활용한 결과물입니다.
낭비 없는 효율적인 공간 활용 (저차원 밀집 벡터)
Section titled “낭비 없는 효율적인 공간 활용 (저차원 밀집 벡터)”분산 표현의 가장 강력한 장점 중 하나는 컴퓨터의 메모리 공간을 극적으로 아껴준다는 것입니다. 단어 사전의 크기가 10,000개라고 가정하고, 그중 인덱스가 4번인 ‘강아지’라는 단어를 두 가지 방식으로 표현해 보겠습니다.
-
과거의 방식 (원-핫 벡터):
강아지 = [0, 0, 0, 0, 1, 0, 0, 0, 0, ..., 0]👉 오직 4번째 칸만 1이고, 그 뒤로 무려 9,995개의 칸이 의미 없는 0으로 낭비됩니다. 단어가 10,000개면 무조건 10,000칸이 필요합니다. (이를 고차원의 희소 표현이라고 합니다.) -
현재의 방식 (분산 표현):
강아지 = [0.2, 0.3, 0.5, -0.7, 0.2, ..., 0.2]👉 사용자가 미리 정해둔 효율적인 개수의 칸(예: 100칸, 300칸 등)만 사용합니다. 그리고 모든 칸이 단어의 의미를 나타내는 실수 값으로 빼곡하게 채워집니다. 단어 사전이 아무리 커져도, 우리가 정해놓은 작은 수의 칸(저차원)만 있으면 충분합니다. (이를 저차원의 밀집 표현이라고 합니다.)
핵심 요약: 왜 분산 표현을 써야 할까요?
Section titled “핵심 요약: 왜 분산 표현을 써야 할까요?”결론적으로 과거의 방식(희소 표현)이 너무 많은 공간(고차원)을 낭비하면서 정작 단어 사이의 의미는 뚝뚝 끊어놓았다면, 분산 표현은 훨씬 적은 공간(저차원)에 단어의 의미를 여러 갈래로 분산시켜 알차게 압축해 놓은 방식입니다.
이렇게 단어를 실수 값으로 꽉 채워 표현하게 되면, 마침내 컴퓨터는 “강아지와 고양이의 벡터 값이 수학적으로 가깝네? 둘은 아주 유사한 의미를 가진 단어구나!” 하고 단어들 사이의 **‘유의미한 유사도’**를 정확하게 계산할 수 있게 됩니다.
4. 의미를 담아내는 방식: 임베딩 벡터 (Embedding Vector)
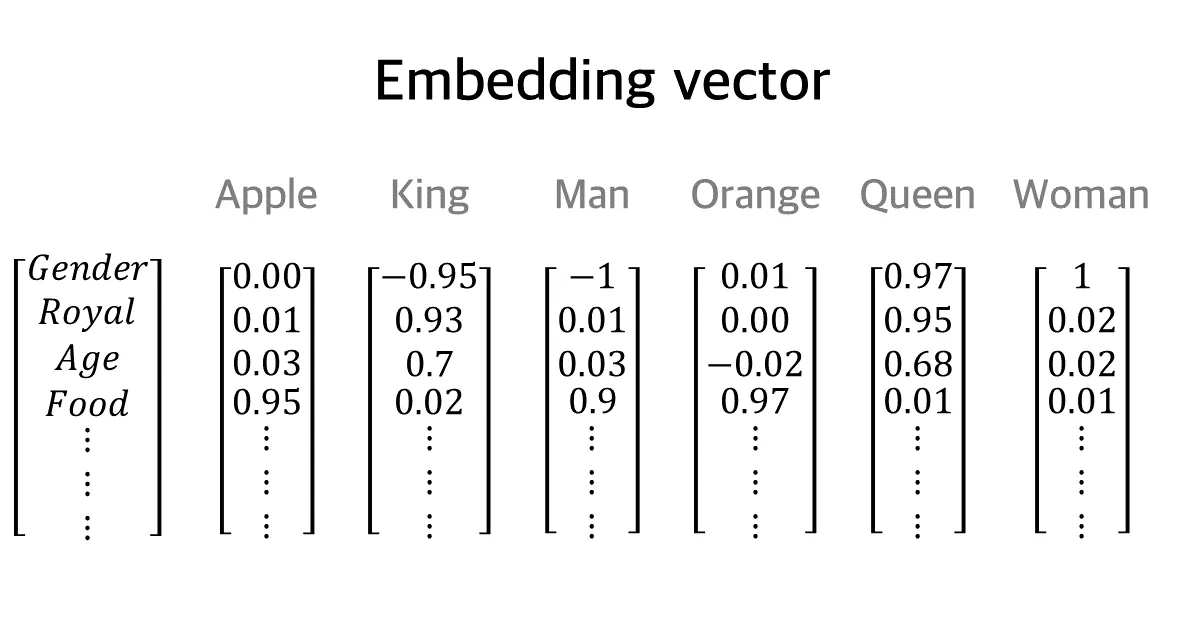
Section titled “4. 의미를 담아내는 방식: 임베딩 벡터 (Embedding Vector)”원-핫 벡터의 ‘의미 없음’을 해결하기 위해 등장한 것이 바로 **임베딩 벡터(Embedding Vector)**입니다. 이 방식은 단어들을 단순한 바코드가 아니라, 여러 가지 특성(성격)에 대한 점수표로 나타냅니다.
마치 게임 캐릭터의 능력치(힘, 민첩, 지능 등)를 숫자로 표현하듯, 단어가 품고 있는 의미를 여러 가지 범주로 나누어 실수 점수를 매기는 것입니다.
-
상반된 의미 표현 (방향성):
예를 들어 ‘성별(Gender)‘이라는 평가 항목이 있다고 해보겠습니다. 여기서 ‘Man(남자)‘은 -1, ‘Woman(여자)‘은 1이라는 점수를 가질 수 있습니다. 여기서 마이너스(-)는 가치가 없다는 뜻이 아니라, 성별이라는 속성에 있어서 두 단어가 정반대의 방향에 위치해 있다는 것을 의미합니다.
-
비슷한 의미 표현 (유사도):
‘왕족(Royal)‘이라는 항목에서는 ‘King(왕)‘이 0.93, ‘Queen(여왕)‘이 0.95라는 점수를 받을 수 있습니다. 컴퓨터는 이 점수를 보고 “두 단어의 점수가 거의 비슷하니까, 둘 다 왕족이라는 아주 비슷한 성격을 공유하고 있구나!”라고 똑똑하게 이해하게 됩니다.
이 방식의 한계점
임베딩 벡터는 단어의 숨은 의미와 관계를 표현하는 데 아주 훌륭합니다. 하지만, 세상에 존재하는 수십만 개의 단어에 대해 사람이 일일이 “이 단어의 성별 점수는 몇 점, 왕족 점수는 몇 점”하고 수작업으로 입력하는 것은 현실적으로 불가능합니다. 천문학적인 시간과 돈이 들기 때문입니다. 그래서 이 점수를 **‘기계가 스스로 알아서 매기게 하는 자동화 방법’**이 필요해졌습니다.
5. 기계가 스스로 의미를 학습하다: Word2Vec
Section titled “5. 기계가 스스로 의미를 학습하다: Word2Vec”이렇게 사람이 직접 점수를 매기기 힘들다는 문제를 해결하기 위해, 구글(Google) 연구진이 발명한 혁신적인 자동 학습 방법이 바로 **Word2Vec (단어를 벡터로 바꾼다는 뜻)**입니다.
Word2Vec의 가장 중요한 핵심 철학은 다음과 같습니다.
“어떤 단어의 의미를 알고 싶다면, 그 단어 주변에 어떤 단어들이 함께 쓰였는지를 보면 된다.” (마치 ‘친구를 보면 그 사람을 알 수 있다’는 속담과 같습니다.)
Word2Vec에는 여러 가지 학습 방식이 있는데, 그중 대표적인 CBOW (Continuous Bag of Words) 방식에 대해 자세히 알아보겠습니다.
빈칸 채우기 놀이 (CBOW 방식의 원리)
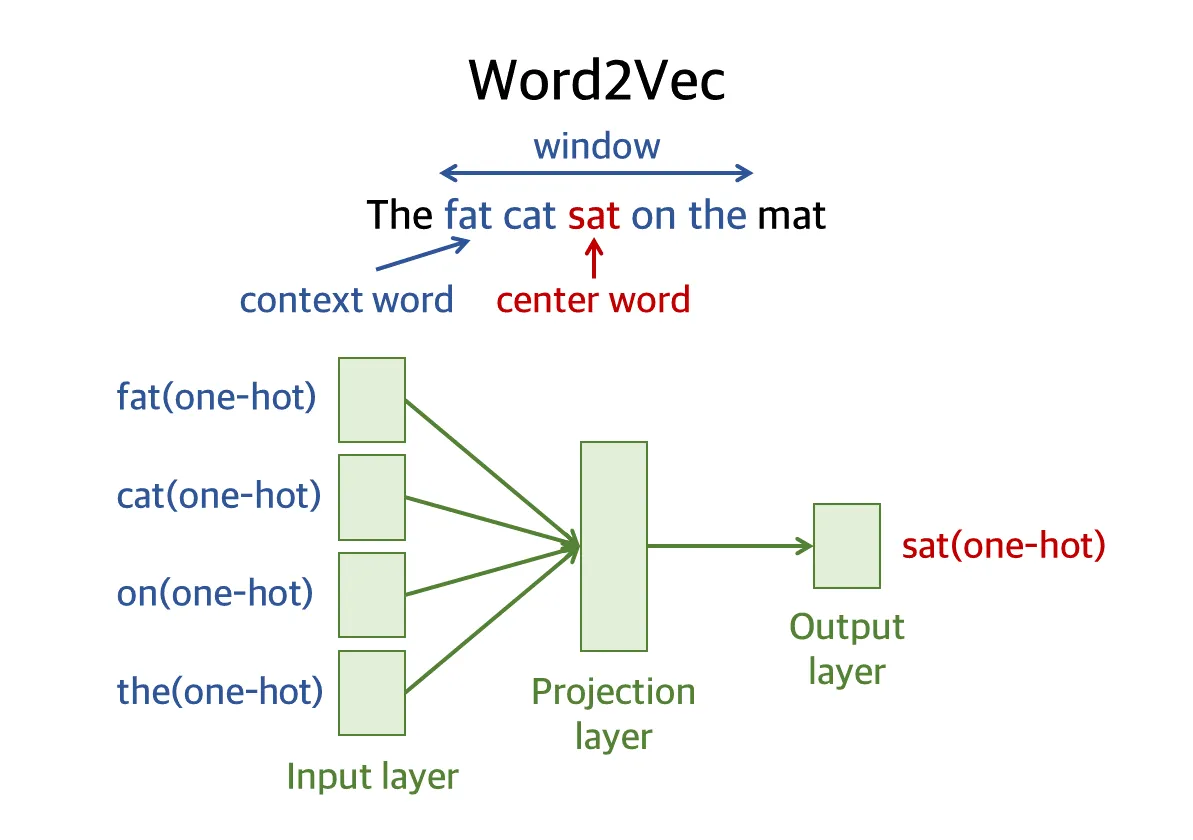
Section titled “빈칸 채우기 놀이 (CBOW 방식의 원리)”CBOW(Continuous Bag-of-Words)는 쉽게 말해 기계에게 **‘빈칸 채우기 문제’**를 계속해서 풀게 하는 방식입니다.
주변에 있는 단어들을 힌트로 주어주고, 한가운데 뚫려있는 빈칸에 들어갈 단어가 무엇일지 기계가 맞추도록 훈련시킵니다.
- 중간 단어 (Center word): 우리가 정답으로 맞춰야 하는 빈칸의 단어입니다.
- 주변 단어 (Context word): 빈칸을 추리하기 위해 힌트로 사용하는 주변 단어들입니다.
- 윈도우 (Window): 힌트를 얻기 위해 정답 단어의 앞뒤로 몇 개의 단어까지 살펴볼 것인지를 정하는 기준 범위입니다. 범위를 넓게 잡으면 문장의 전반적인 흐름을 넓게 보게 되고, 좁게 잡으면 바로 옆에 있는 단어와의 긴밀한 관계에 집중하게 됩니다.
CBOW는 어떻게 학습을 진행할까요?
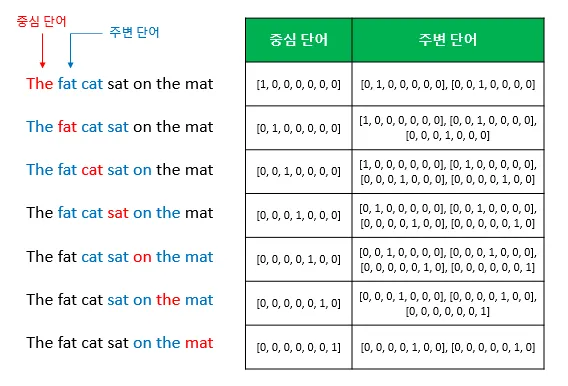
Section titled “CBOW는 어떻게 학습을 진행할까요?”예를 들어 **“the cat sat on the mat (고양이가 매트 위에 앉았다)“**라는 문장이 있다고 해보겠습니다. 여기서 기계가 **“sat(앉았다)“**라는 단어를 맞춰야 하는 상황입니다. (힌트 단어는 “the”, “cat”, “on”, “the” 입니다.)
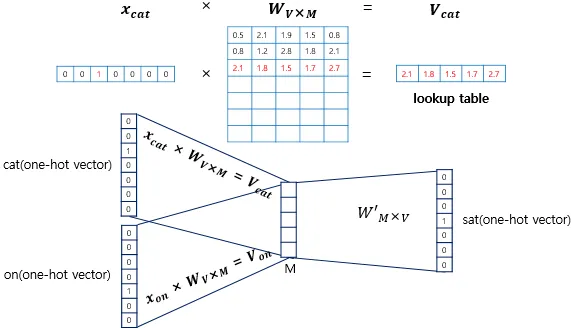
-
입력층 (힌트 단어 넣기):
먼저 힌트가 되는 주변 단어들(“the”, “cat”, “on”, “the”)을 앞서 배웠던 단순한 형태인 ‘원-핫 벡터(0과 1로 된 리스트)‘로 바꾸어 기계에 입력으로 넣어줍니다. -
투사층 (의미를 압축하고 변환하기 - 핵심 단계):
기계는 입력받은 주변 단어들의 원-핫 벡터들을 한데 모아서 평균을 냅니다. 그리고 이 평균값을 **‘임베딩 행렬(변환기)‘**이라는 특별한 필터를 통과시킵니다.수만 개의 0으로 채워져 있던 텅 빈 원-핫 벡터는 이 필터를 거치면서, 크기는 작아지지만 의미 있는 숫자들이 꽉꽉 채워진 형태(임베딩 벡터)로 꾹 압축됩니다.
-
출력층 (정답 예측 및 스스로 오답 노트 작성하기):
압축된 정보를 바탕으로, 기계는 가운데 빈칸에 들어갈 단어가 “sat”일 것이라고 예측합니다.
처음에는 기계가 아무것도 모르기 때문에 엉뚱한 단어를 말할 확률이 높습니다. 그러면 기계는 실제 정답(“sat”)과 자신이 예측한 단어를 비교해서 **‘오차(틀린 정도)‘**를 계산합니다.그리고 틀린 만큼, 2번 단계에 있었던 ‘임베딩 행렬(변환기)‘의 수치들을 조금씩 수정합니다. (이를 역전파 알고리즘이라고 합니다.)
이러한 ‘빈칸 맞추기 -> 틀림 -> 변환기 점수 수정 -> 빈칸 맞추기’ 과정을 수백만 개의 문장을 읽으며 무한히 반복합니다. 이 혹독한 훈련이 끝나면, 기계의 변환기(임베딩 행렬)는 단어들의 미묘한 뉘앙스와 문맥을 기가 막히게 이해할 수 있는 **완벽한 단어 사전(임베딩 테이블)**으로 진화하게 됩니다.
6. 백문이 불여일견! 단어로 수학 연산 실습
Section titled “6. 백문이 불여일견! 단어로 수학 연산 실습”지금까지 우리는 과거의 원-핫 벡터 방식은 단어들 사이의 유사도를 전혀 계산할 수 없었지만, Word2Vec을 이용한 ‘분산 표현’ 방식은 단어의 의미를 수치화하여 벡터 공간에 훌륭하게 배치할 수 있다고 배웠습니다.
그렇다면 컴퓨터가 단어의 의미를 숫자로 제대로 이해했는지, 우리 눈으로 직접 확인해 볼 수 있는 방법이 있을까요? 놀랍게도 **‘단어를 가지고 더하기, 빼기와 같은 수학 연산을 해보는 것’**입니다.
강의를 들으시는 여러분도 직접 한국어 단어 벡터 연산을 테스트해 볼 수 있는 유용한 사이트가 있습니다. (URL: http://w.elnn.kr/search/ ) 이 사이트의 검색창에 단어들을 더하고 빼는 수식을 입력하면, Word2Vec으로 학습된 컴퓨터가 계산 결과를 단어로 대답해 줍니다.
단어 연산의 놀라운 예시들
Section titled “단어 연산의 놀라운 예시들”가장 대표적이고 신기한 두 가지 예시를 살펴보겠습니다.
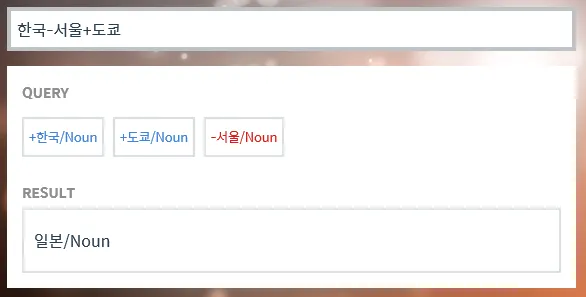
예시 1) 국가와 수도의 관계
한국 - 서울 + 도쿄 = ?
이 수식을 입력하면 컴퓨터는 어떤 대답을 내놓을까요? 정답은 바로 **‘일본’**입니다. 컴퓨터가 생각한 연산의 과정은 이렇습니다.
- ‘한국’이라는 단어가 가진 수많은 속성 중에서, ‘서울’이라는 단어의 속성(한국의 수도)을 뺍니다(-).
- 그러면 수도라는 개념이 사라진 어떤 추상적인 벡터 공간이 남습니다.
- 여기에 ‘도쿄’라는 단어의 속성(일본의 수도)을 더합니다(+).
- 그 결과 도달하게 된 최종 벡터 좌표와 가장 가까운 단어를 찾아보니 **‘일본’**이 나오는 것입니다. 컴퓨터가 ‘국가’와 ‘수도’ 사이의 관계(방향성)를 정확히 이해하고 있다는 증거입니다.
예시 2) 스포츠와 선수의 관계
박찬호 - 야구 + 축구 = ?
이 수식의 결과는 무엇일까요? 정답은 바로 전설적인 축구 선수인 ‘호나우두’ (또는 유명 축구 선수)입니다.
- ‘박찬호’라는 단어에서 ‘야구’라는 종목의 특성을 뺍니다(-). (그러면 ‘한 시대를 풍미한 위대한 스포츠 선수’라는 속성 정도만 남게 될 것입니다.)
- 그 상태에서 ‘축구’라는 종목의 특성을 새롭게 더합니다(+).
- 컴퓨터는 이 결과값과 가장 유사한 단어로 위대한 축구 선수인 ‘호나우두’를 도출해 냅니다.
이것이 가능한 진짜 이유
Section titled “이것이 가능한 진짜 이유”어떻게 단어를 가지고 이런 마법 같은 연산이 가능한 것일까요?
그 이유는 앞서 배운 ‘분산 표현(Distributed Representation)’ 덕분입니다. Word2Vec을 통해 훈련된 단어들은 단순히 의미 없는 숫자가 아니라, 저마다 ‘의미의 방향과 거리’를 담은 정교한 좌표 값을 가지고 있기 때문입니다. 단어 벡터 간의 유의미한 유사도가 수치적으로 완벽하게 반영되어 있기에, 컴퓨터가 단어들의 관계를 수학 공식처럼 더하고 뺄 수 있는 것입니다.
## 7. 실전: 오늘날 우리는 임베딩을 어떻게 사용할까요? (사전 학습 모델과 인덱싱)
Section titled “## 7. 실전: 오늘날 우리는 임베딩을 어떻게 사용할까요? (사전 학습 모델과 인덱싱)”지금까지 우리는 단어를 벡터로 바꾸는 원리와 Word2Vec의 학습 방법에 대해 알아보았습니다. 그렇다면 현업에서 개발자나 데이터 과학자들은 매번 이런 복잡한 학습 과정을 밑바닥부터 직접 진행할까요?
정답은 **“아니오”**입니다.
7.1. 거인들의 어깨 위로: 사전 학습 모델(Pre-trained Model)의 활용
Section titled “7.1. 거인들의 어깨 위로: 사전 학습 모델(Pre-trained Model)의 활용”오늘날 AI 서비스를 개발할 때 ‘임베딩 모델을 사용한다’는 것은, 구글, 마이크로소프트, 오픈AI와 같은 글로벌 빅테크 기업들이 어마어마한 양의 텍스트 데이터와 컴퓨팅 자원을 쏟아부어 미리 똑똑하게 학습시켜 놓은 ‘사전 학습 모델(Pre-trained Model)‘을 가져다 쓴다는 것을 의미합니다.
우리는 그저 이 완성된 모델에 우리가 가진 텍스트(문장이나 문서)를 집어넣기만 하면 됩니다. 그러면 모델은 즉각적으로 수백~수천 개의 숫자로 이루어진 고품질의 ‘임베딩 벡터’를 뱉어냅니다. 이미 세상의 수많은 언어와 문맥을 이해하고 있는 사전 모델을 이용하기 때문에, 우리는 아주 간단하고 빠르게 최고 수준의 임베딩 결과를 얻을 수 있습니다.
7.2. 초고속 검색의 비밀: 벡터 인덱싱(Vector Indexing)
Section titled “7.2. 초고속 검색의 비밀: 벡터 인덱싱(Vector Indexing)”이렇게 뽑아낸 수많은 텍스트의 임베딩 벡터들은 어디에 쓰일까요? 주로 **‘벡터 데이터베이스(Vector DB)‘**라는 특수한 저장소에 저장됩니다. (Elasticsearch, Milvus 등이 대표적입니다.)
이 과정에서 텍스트를 벡터로 변환하여 DB에 차곡차곡 정리해 두는 것을 **‘인덱싱(Indexing)‘**이라고 부릅니다. 책의 맨 뒤에 있는 ‘색인(Index)‘을 보고 원하는 내용을 빠르게 찾듯, 문서들을 수치화된 벡터 좌표로 인덱싱해 두면 컴퓨터는 수백만 개의 문서 중에서도 내가 질문한 내용과 ‘의미적으로 가장 가까운(유사도가 높은)’ 문서를 단 0.1초 만에 족집게처럼 찾아낼 수 있습니다. 최근 유행하는 RAG(검색 증강 생성) 기술의 핵심이 바로 이 빠르고 강력한 벡터 인덱싱에 있습니다.
8. 최신 유명 임베딩 모델과 차원(Dimension) 소개
Section titled “8. 최신 유명 임베딩 모델과 차원(Dimension) 소개”그렇다면 현재 실무에서 가장 널리 쓰이는 대표적인 임베딩 모델들에는 어떤 것들이 있을까요? 임베딩 모델을 선택할 때는 서비스의 목적에 따라 API로 제공되는 LLM 모델을 쓸지, 아니면 서버에 직접 설치해서 무료로 쓰는 로컬 모델을 쓸지 결정하게 됩니다.
여기서 **‘차원(Dimension)‘**이란 단어의 의미를 담아내는 실수 숫자의 개수(칸 수)를 말합니다. 차원이 클수록 더 정교한 의미를 담을 수 있지만, 저장 공간도 더 많이 차지하게 됩니다.
8.1. API 기반 상용 LLM 임베딩 모델 (클라우드 제공)
Section titled “8.1. API 기반 상용 LLM 임베딩 모델 (클라우드 제공)”인터넷을 통해 호출해서 쓰는 방식으로, 성능이 매우 뛰어나고 관리가 편합니다.
-
OpenAI (text-embedding-3 시리즈): 현재 가장 대중적으로 쓰이는 임베딩 API입니다. 가볍고 빠른
text-embedding-3-small모델은 1536 차원을 사용하며, 더 깊은 이해력이 필요한 경우text-embedding-3-large모델을 사용하여 최대 3072 차원까지 조절할 수 있습니다. -
Google (gemini-embedding-2-preview): 텍스트, 이미지, 비디오, 오디오, 문서(PDF)를 모두 단일 벡터 공간으로 통합하는 구글의 최신 네이티브 멀티모달 임베딩 모델입니다. 기본적으로 3,072 차원을 출력(유연한 차원 축소 지원)하며, 긴 컨텍스트(최대 8,192 토큰)를 바탕으로 데이터의 형태와 상관없이 매우 뛰어난 교차 검색(Cross-modal) 성능을 보여줍니다.
-
Cohere (embed-multilingual-v3.0): 한국어를 포함한 다국어 검색 성능이 매우 뛰어난 모델로, 1024 차원을 사용합니다.
8.2. 로컬(Local) 및 오픈소스 임베딩 모델
Section titled “8.2. 로컬(Local) 및 오픈소스 임베딩 모델”보안 문제로 데이터를 외부 서버로 보낼 수 없거나, 비용을 절감하기 위해 내 컴퓨터나 사내 서버에 직접 설치해서 사용하는 모델들입니다.
-
Microsoft E5 시리즈 (multilingual-e5-large 등): 마이크로소프트(MS) 연구진이 공개하여 현재 로컬 생태계에서 가장 유명하고 강력한 오픈소스 모델 중 하나입니다. 다국어를 완벽히 지원하며, 주로 1024 차원이나 768 차원을 사용합니다. 오픈소스임에도 상용 모델에 뒤지지 않는 압도적인 문맥 파악 능력을 자랑합니다.
-
BAAI BGE 시리즈 (bge-m3): 중국 베이징인공지능연구원(BAAI)에서 만든 모델로, 다국어 처리와 긴 문장 처리에 매우 강합니다. 1024 차원을 가지며 로컬 RAG 시스템을 구축할 때 MS E5와 함께 1, 2위를 다투는 인기 모델입니다.
-
Alibaba GTE 시리즈 (gte-multilingual-base 등): 70개 이상의 언어와 긴 컨텍스트(최대 8,192 토큰)를 지원하는 알리바바(Alibaba) 연구진이 공개한 모델로, 최근 오픈소스 생태계에서 새롭게 떠오르는 강자입니다. 768 차원을 사용하며, 이 모델의 가장 강력한 장점은 극강의 ‘효율성’입니다. 모델이 매우 가볍고 최적화가 잘 되어 있어서, 고가의 외장 그래픽카드(GPU)가 없어도 일반적인 CPU 환경에서 아주 빠르고 원활하게 동작합니다. 인프라 구축 비용이 부담되거나 가벼운 사양의 서버에서 다국어 임베딩을 구현해야 할 때 최우선으로 고려해 볼 수 있는 훌륭한 선택지입니다.