05 RAG에 대한 이해
1. 우리의 AI를 더 똑똑하게: RAG(검색 증강 생성)의 이해
Section titled “1. 우리의 AI를 더 똑똑하게: RAG(검색 증강 생성)의 이해”1.1. LLM의 치명적인 두 가지 약점
Section titled “1.1. LLM의 치명적인 두 가지 약점”우리가 쓰는 ChatGPT나 Gemini 같은 대형 언어 모델(LLM)은 천재이지만, 치명적인 두 가지 약점을 가지고 있습니다.
-
할루시네이션 (Hallucination - 거짓말): AI는 학습한 데이터 내에서 대답합니다. 모르는 내용이나 학습하지 않은 내용을 물어보면, 당황하지 않고 매우 그럴듯한 거짓말을 지어냅니다.
-
내부 데이터/최신 정보 부재: AI 모델은 학습이 끝난 순간의 정보만 기억합니다. 우리 회사의 어제 나온 신상품 데이터나, 회사 내부 기밀 상품 데이터는 당연히 모릅니다.
1.2. RAG(Retrieval-Augmented Generation)란 무엇일까요?
Section titled “1.2. RAG(Retrieval-Augmented Generation)란 무엇일까요?”RAG는 **‘검색 증강 생성’**의 약자입니다. 쉽게 비유하자면, AI에게 ‘오픈북 테스트’를 시키는 기술이라고 생각하시면 됩니다.
-
Normal LLM: 머릿속의 지식만으로 시험을 봅니다 (폐쇄형 학습). 거짓말을 하거나 최신 정보를 모릅니다.
-
RAG: 시험을 보다가 모르는 문제가 나오면, 미리 준비된 ‘참고서(우리의 상품 데이터베이스)‘를 뒤져서 정답을 찾은 뒤, 그 정보를 바탕으로 완벽한 답안지를 작성합니다.
즉, ‘검색(Retrieval)’ 기술을 이용해 AI의 지식을 **‘증강(Augmented)‘**시킨 뒤, 대답을 **‘생성(Generation)‘**하게 만드는 구조입니다.
1.3. RAG 시스템의 전체적인 구조 (오픈북 테스트 과정)
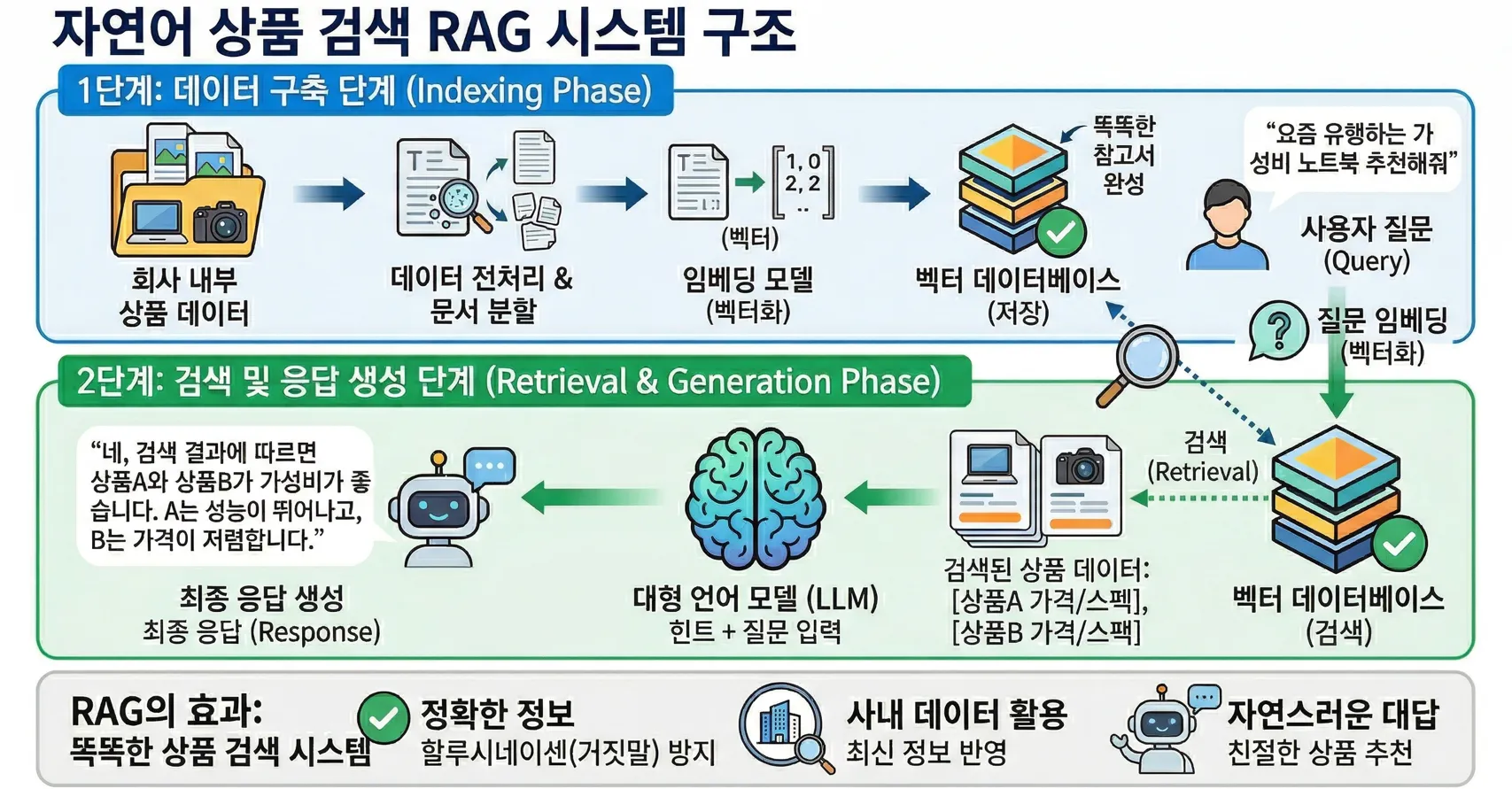
Section titled “1.3. RAG 시스템의 전체적인 구조 (오픈북 테스트 과정)”RAG 시스템이 어떻게 우리의 상품 데이터를 뒤져서 똑똑하게 대답하는지, 전체적인 흐름을 아주 쉽게 설명해 드리겠습니다. 아래 이미지를 보면서 함께 따라오세요.
1단계: 참고서 만들기 (데이터 구축 단계 - Indexing)
Section titled “1단계: 참고서 만들기 (데이터 구축 단계 - Indexing)”우선 AI가 검색할 수 있는 ‘똑똑한 참고서’를 미리 만들어야 합니다.
- 회사 내부 상품 데이터: 우리의 엑셀, PDF, DB 등에 저장된 상품 정보들을 가져옵니다.
- 문서 분할: 너무 긴 문서는 검색하기 힘드므로, 의미 있는 조각(토큰)으로 자릅니다.
- 임베딩(벡터화) ⭐️: 우리가 배운 그 기술입니다! 각 상품 조각의 의미를 담은 **‘벡터’**로 변환합니다.
- 벡터 데이터베이스 (저장): 이 벡터 값들을 나중에 유사도로 검색할 수 있도록 **‘벡터 데이터베이스’**에 차곡차곡 인덱싱(정리)해서 저장해 둡니다.
2단계: 질문 & 응답 (실시간 검색 단계 - Retrieval & Generation)
Section titled “2단계: 질문 & 응답 (실시간 검색 단계 - Retrieval & Generation)”이제 사용자가 질문을 던졌을 때 일어나는 일입니다.
-
사용자 질문 (Query): “요즘 유행하는 가성비 노트북 추천해줘” 같은 자연어 질문이 들어옵니다.
-
질문 임베딩: 이 질문 역시 의미를 분석하기 위해 **‘질문 벡터’**로 변환합니다.
-
벡터 DB 검색 (Retrieval) ⭐️: 우리가 저장해 둔 벡터 DB로 가서, 질문 벡터와 ‘코사인 유사도’가 가장 높은(방향이 가장 비슷한) 상품 벡터들을 순식간에 찾아냅니다. (예: 상품A, 상품B의 가격과 스펙 정보 추출)
-
프롬프트 구성 (Prompt): 이제 AI의 뇌로 정보를 전달합니다. 그냥 질문만 던지는 것이 아니라, 검색된 정보들을 **‘힌트(문맥)‘**로 넣어줍니다.
“질문: 가성비 노트북 추천 / 검색된 힌트: [상품A 가격/스펙], [상품B 가격/스펙]… / 위 힌트를 바탕으로 친절하게 대답해줘.”
-
최종 응답 생성 (Generation): LLM은 이제 힌트라는 완벽한 참고서를 가지고 있습니다. 할루시네이션 없이, 검색된 실제 데이터를 바탕으로 정확하고 자연스러운 대답을 생성해 줍니다.
“네, 검색된 정보에 따르면 상품A와 상품B가 가장 가성비가 좋습니다. A는 성능이 뛰어나고, B는 가격이 저렴합니다.”
💡 핵심 요약
Section titled “💡 핵심 요약”RAG는 **“무작정 대답하지 않고, 먼저 물어보고 정보를 가져와서 대답하는 똑똑한 AI”**입니다. 이 구조를 이용하면 우리는 AI에게 우리의 모든 상품 지식을 가르칠 수 있습니다.